



La RT-qPCR est développée à partir de la technologie PCR ordinaire.Il ajoute des produits chimiques fluorescents (colorants fluorescents ou sondes fluorescentes) au système de réaction PCR traditionnel et détecte le processus d'annelage et d'extension PCR en temps réel en fonction de leurs différents mécanismes luminescents.Les changements de signal fluorescent dans le milieu sont utilisés pour calculer la quantité de changement de produit dans chaque cycle de PCR.Actuellement, les méthodes les plus courantes sont la méthode du colorant fluorescent et la méthode de la sonde.
Méthode de teinture fluorescente :
Certains colorants fluorescents, tels que SYBR Green Ⅰ, PicoGreen, BEBO, etc., n'émettent pas de lumière par eux-mêmes, mais émettent une fluorescence après s'être liés au petit sillon de l'ADNdb.Par conséquent, au début de la réaction PCR, la machine ne peut pas détecter le signal fluorescent.Lorsque la réaction passe à l'annealing-extension (méthode en deux étapes) ou à l'étape d'extension (méthode en trois étapes), les doubles brins sont ouverts à ce moment, et la nouvelle ADN polymérase Pendant la synthèse des brins, les molécules fluorescentes sont combinées dans le sillon mineur de l'ADNdb et émettent une fluorescence.À mesure que le nombre de cycles de PCR augmente, de plus en plus de colorants se combinent avec l'ADNdb, et le signal fluorescent est également continuellement amélioré.Prenez SYBR Green Ⅰ comme exemple.
Méthode de sonde :
La sonde Taqman est la sonde d'hydrolyse la plus couramment utilisée.Il y a un groupe fluorescent à l'extrémité 5 'de la sonde, généralement FAM.La sonde elle-même est une séquence complémentaire du gène cible.Il existe un groupe d'extinction fluorescent à l'extrémité 3 'du fluorophore.Selon le principe du transfert d'énergie de résonance de fluorescence (Förster resonance energy transfer, FRET), lorsque le groupe fluorescent rapporteur (molécule fluorescente donneuse) et le groupe fluorescent quenching (molécule fluorescente acceptrice) Lorsque le spectre d'excitation se chevauche et que la distance est très proche (7-10nm), l'excitation de la molécule donneuse peut induire la fluorescence de la molécule acceptrice, tandis que l'autofluorescence est affaiblie.Par conséquent, au début de la réaction PCR, lorsque la sonde est libre et intacte dans le système, le groupe fluorescent rapporteur n'émettra pas de fluorescence.Lors de l'annelage, l'amorce et la sonde se lient à la matrice.Au cours de l'étape d'extension, la polymérase synthétise en continu de nouvelles chaînes.L'ADN polymérase a une activité d'exonucléase 5'-3'.Lorsqu'elle atteint la sonde, l'ADN polymérase hydrolyse la sonde de la matrice, sépare le groupe fluorescent rapporteur du groupe fluorescent extincteur et libère le signal fluorescent.Puisqu'il existe une relation biunivoque entre la sonde et la matrice, la méthode de la sonde est supérieure à la méthode du colorant en termes de précision et de sensibilité du test.
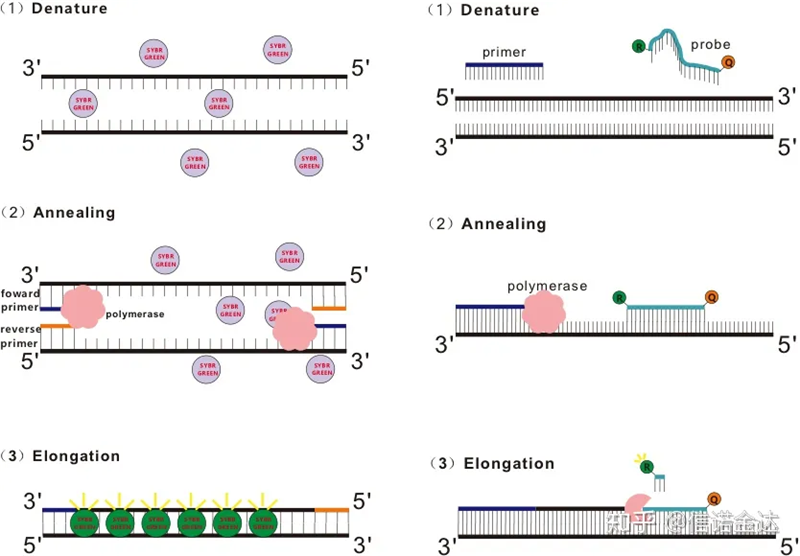
Fig 1 Principe de la qRT-PCR
Conception d'apprêt
Des principes:
Les amorces doivent être conçues dans la région conservée de la série d'acides nucléiques et avoir une spécificité.
Il est préférable d'utiliser la séquence d'ADNc, et la séquence d'ARNm est également acceptable.Si ce n'est pas le cas, découvrez la conception de la région cds de la séquence d'ADN.
La longueur du produit quantitatif fluorescent est de 80 à 150 pb, la plus longue est de 300 pb, la longueur de l'amorce est généralement comprise entre 17 et 25 bases et la différence entre les amorces en amont et en aval ne doit pas être trop grande.
La teneur en G+C se situe entre 40 % et 60 %, et 45-55 % est la meilleure.
La valeur TM est comprise entre 58 et 62 degrés.
Essayez d'éviter les dimères d'amorce et les auto-dimensions, (n'apparaissez pas plus de 4 paires de bases complémentaires consécutives) Structure en épingle à cheveux, si inévitable, rendez ΔG <4,5 kJ / mol * Si vous ne pouvez pas vous assurer que la GDNA a été supprimée pendant la transcription inverse propre, il est préférable de concevoir les amorces de l'intron * 3 'ne peut pas être modifié, et pour éviter, GC Regitions, GC, GC, GC, GC, T / C, C / C, C / C. ) amorces et non
spécifique L'homologie de la séquence amplifiée de manière hétérogène est de préférence inférieure à 70 % ou présente une homologie de 8 bases complémentaires.
Base de données:
CottonFGD recherche par mots-clés
Conception de l'apprêt :
Conception d'amorce IDT-qPCR
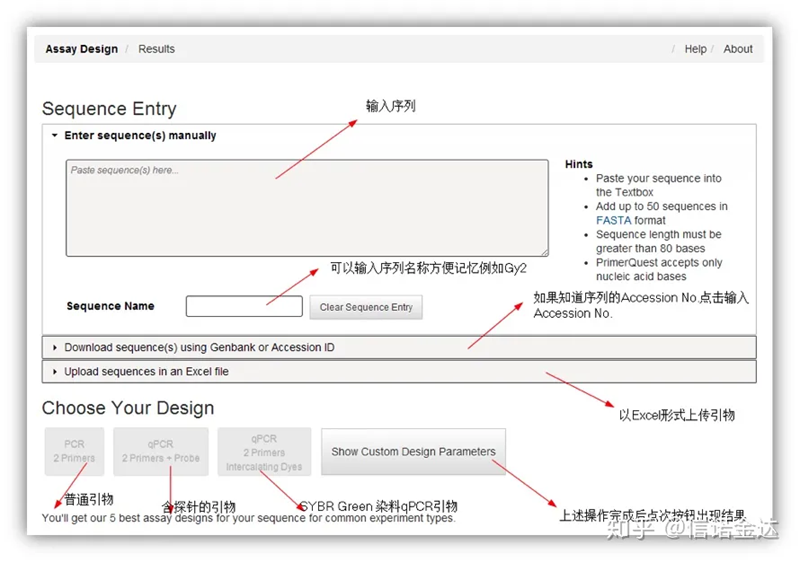
Fig2 Page de l'outil de conception d'amorce en ligne IDT
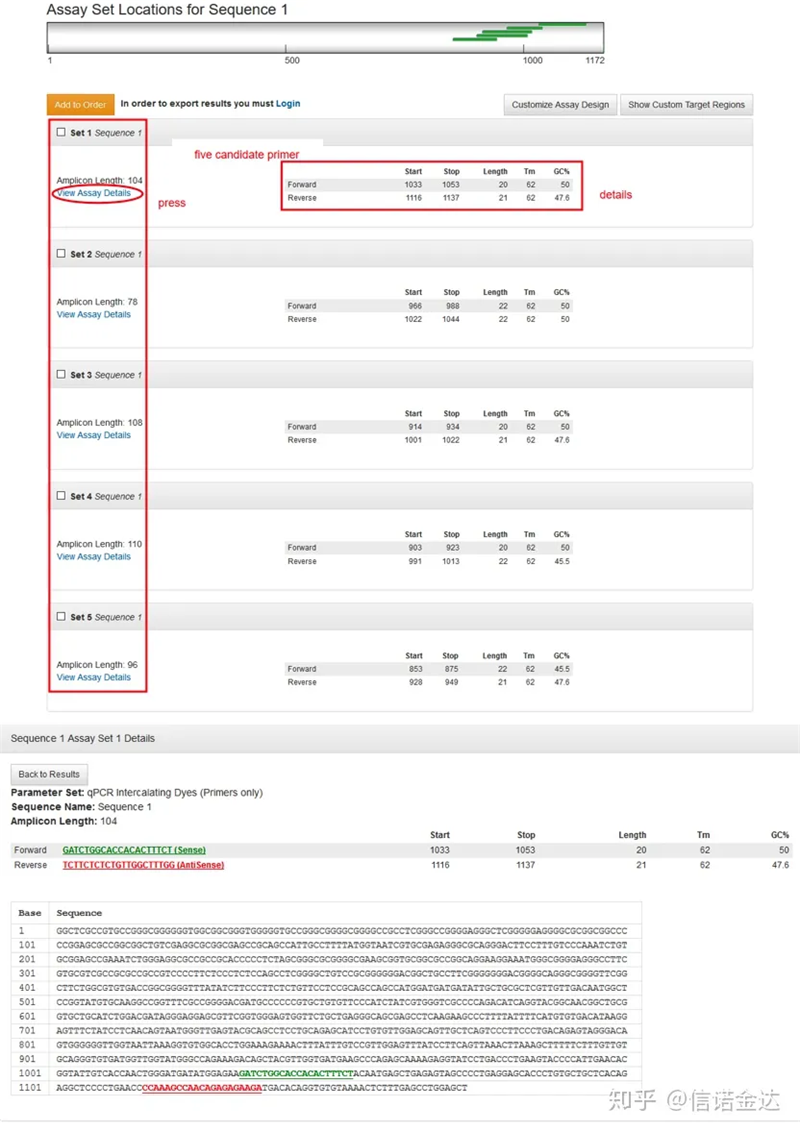
Affichage de la page de résultats Fig3
Conception d'amorces lncRNA :
lncRNA :les mêmes étapes que l'ARNm.
miARN :Le principe de la méthode tige-boucle : Étant donné que tous les miARN sont de courtes séquences d'environ 23 nt, la détection directe par PCR ne peut pas être effectuée, donc l'outil de séquence tige-boucle est utilisé.La séquence tige-boucle est un ADN simple brin d'environ 50 nt, qui peut former une structure en épingle à cheveux par lui-même.3' L'extrémité peut être conçue comme une séquence complémentaire du fragment partiel de miARN, puis le miARN cible peut être connecté à la séquence tige-boucle lors de la transcription inverse, et la longueur totale peut atteindre 70 pb, ce qui est en ligne avec la longueur du produit amplifié déterminée par qPCR.Conception d'amorces de miARN de queue.
Détection spécifique à l'amplification :
Base de données de blast en ligne : blast CottonFGD par similarité de séquence
Explosion locale : reportez-vous à l'utilisation de Blast+ pour effectuer une explosion locale, Linux et macos peuvent établir directement une base de données locale, le système win10 peut également être effectué après l'installation d'ubuntu bash.Créer une base de données de souffle locale et un souffle local ;ouvrez ubuntu bash sur win10.
Remarque : Le coton upland et le coton des îles maritimes sont des cultures tétraploïdes, de sorte que le résultat de la dynamitage sera souvent deux ou plusieurs correspondances.Dans le passé, l'utilisation des cd NAU comme base de données pour effectuer le blast est susceptible de trouver deux gènes homologues avec seulement quelques différences de SNP.Habituellement, les deux gènes homologues ne peuvent pas être séparés par la conception d'amorces, ils sont donc traités comme identiques.S'il y a un indel évident, l'amorce est généralement conçue sur l'indel, mais cela peut conduire à la structure secondaire de l'amorce. L'énergie libre devient plus élevée, entraînant une diminution de l'efficacité d'amplification, mais cela est inévitable.
Détection de la structure secondaire de l'amorce :
Pas:ouvrir oligo 7 → séquence de modèle d'entrée → fermer la sous-fenêtre → enregistrer → localiser l'amorce sur le modèle, appuyer sur ctrl + D pour définir la longueur de l'amorce → analyser diverses structures secondaires, telles que le corps d'auto-dimérisation, l'hétérodimère, l'épingle à cheveux, l'inadéquation, etc. Les deux dernières images de la figure 4 sont les résultats des tests des amorces.Le résultat de l'amorce avant est bon, il n'y a pas de structure évidente de dimère et d'épingle à cheveux, pas de bases complémentaires continues, et la valeur absolue de l'énergie libre est inférieure à 4,5, tandis que l'amorce arrière montre une continuité. Les 6 bases sont complémentaires et l'énergie libre est de 8,8 ;de plus, un dimère plus grave apparaît à l'extrémité 3', et un dimère de 4 bases consécutives apparaît.Bien que l'énergie libre ne soit pas élevée, le dimère 3' Chl peut sérieusement affecter la spécificité et l'efficacité de l'amplification.De plus, il est nécessaire de vérifier les épingles à cheveux, les hétérodimères et les mésappariements.
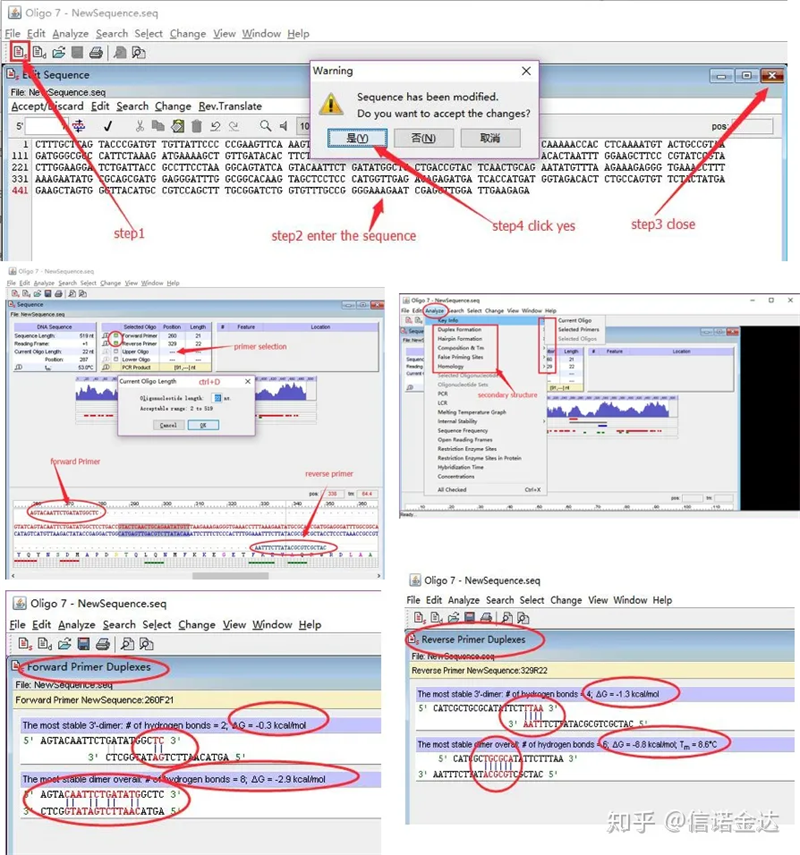
Fig3 oligo7 résultats de détection
Détection d'efficacité d'amplification :
L'efficacité d'amplification de la réaction PCR affecte sérieusement les résultats de la PCR.Toujours en qRT-PCR, l'efficacité de l'amplification est particulièrement importante pour les résultats quantitatifs.Retirez les autres substances, machines et protocoles du tampon de réaction.La qualité des amorces a également une grande influence sur l'efficacité d'amplification de la qRT-PCR.Afin d'assurer l'exactitude des résultats, la quantification de fluorescence relative et la quantification de fluorescence absolue doivent détecter l'efficacité d'amplification des amorces.Il est reconnu que l'efficacité d'amplification qRT-PCR efficace est comprise entre 85% et 115%.Il existe deux méthodes :
1. Méthode de la courbe standard :
un.Mélanger l'ADNc
b.Dégradé de dilution
c.qPCR
d.Équation de régression linéaire pour calculer l'efficacité d'amplification
2. LinRegPCR
LinRegPCR est un programme d'analyse de données RT-PCR en temps réel, également appelées données PCR quantitatives (qPCR) basées sur SYBR Green ou une chimie similaire.Le programme utilise des données corrigées non de référence, effectue une correction de référence sur chaque échantillon séparément, détermine une fenêtre de linéarité, puis utilise une analyse de régression linéaire pour ajuster une ligne droite à travers l'ensemble de données PCR.À partir de la pente de cette ligne, l'efficacité de la PCR de chaque échantillon individuel est calculée.L'efficacité PCR moyenne par amplicon et la valeur Ct par échantillon sont utilisées pour calculer une concentration de départ par échantillon, exprimée en unités de fluorescence arbitraires.L'entrée et la sortie des données se font via une feuille de calcul Excel.Seul échantillon
un mélange est nécessaire, pas de gradient
étapes sont nécessaires :(Prenez Bole CFX96 comme exemple, pas tout à fait une machine avec un ABI clair)
expérience:c'est une expérience qPCR standard.
Sortie de données qPCR :LinRegPCR peut reconnaître deux formes de fichiers de sortie : RDML ou résultat d'amplification de quantification.En fait, il s'agit de la valeur de détection en temps réel du nombre de cycles et du signal de fluorescence par la machine, et l'amplification est obtenue en analysant la valeur de changement de fluorescence de l'efficacité du segment linéaire.
Sélection des données: En théorie, la valeur RDML devrait être utilisable.On estime que le problème de mon ordinateur est que le logiciel ne peut pas reconnaître RDML, j'ai donc la valeur de sortie Excel comme données d'origine.Il est recommandé d'effectuer d'abord un dépistage grossier des données, comme l'échec de l'ajout d'échantillons, etc. Les points peuvent être supprimés dans les données de sortie (bien sûr, vous ne pouvez pas les supprimer, LinRegPCR ignorera ces points à l'étape ultérieure)
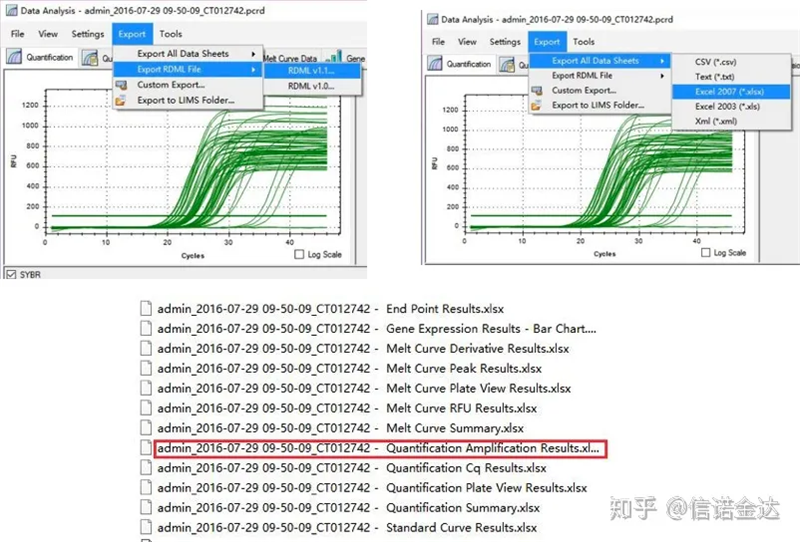
Fig5 Exportation de données qPCR
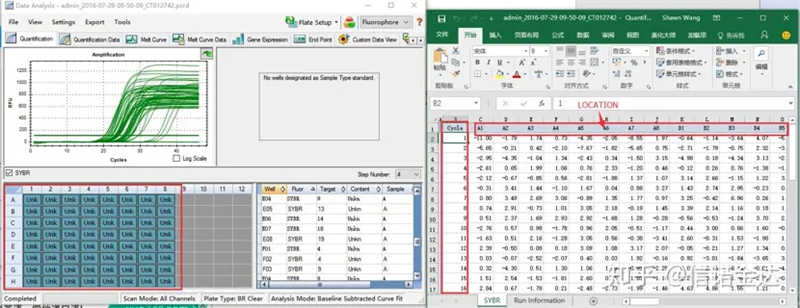
Fig6 sélection des échantillons candidats
Entrée de données:Ouvrez les résultats d'amplification de qualification.xls, → ouvrez LinRegPCR → fichier → lisez à partir d'Excel → sélectionnez les paramètres comme illustré à la figure 7 → OK → cliquez sur déterminer les lignes de base
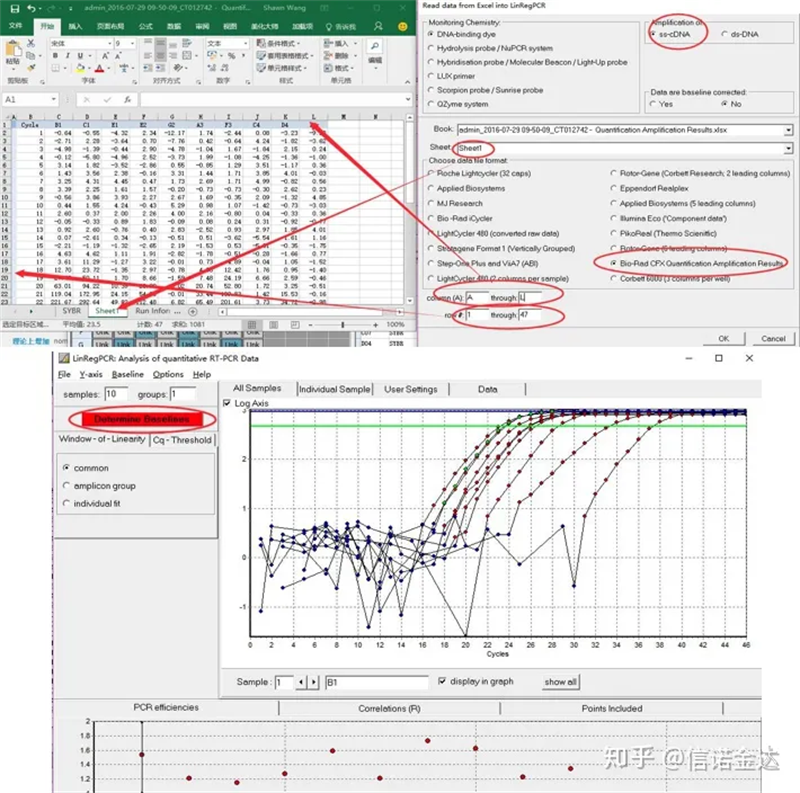
Fig7 étapes de l'entrée de données linRegPCR
Résultat:S'il n'y a pas de répétition, aucun regroupement n'est requis.S'il y a répétition, le groupement peut être modifié dans le groupement d'échantillons, et le nom du gène est entré dans l'identifiant, puis le même gène sera automatiquement groupé.Enfin, cliquez sur le fichier, exportez Excel et visualisez les résultats.L'efficacité d'amplification et les résultats R2 de chaque puits seront affichés.Deuxièmement, si vous vous divisez en groupes, l'efficacité d'amplification moyenne corrigée sera affichée.Assurez-vous que l'efficacité d'amplification de chaque amorce est comprise entre 85 % et 115 %.S'il est trop grand ou trop petit, cela signifie que l'efficacité d'amplification de l'amorce est mauvaise.
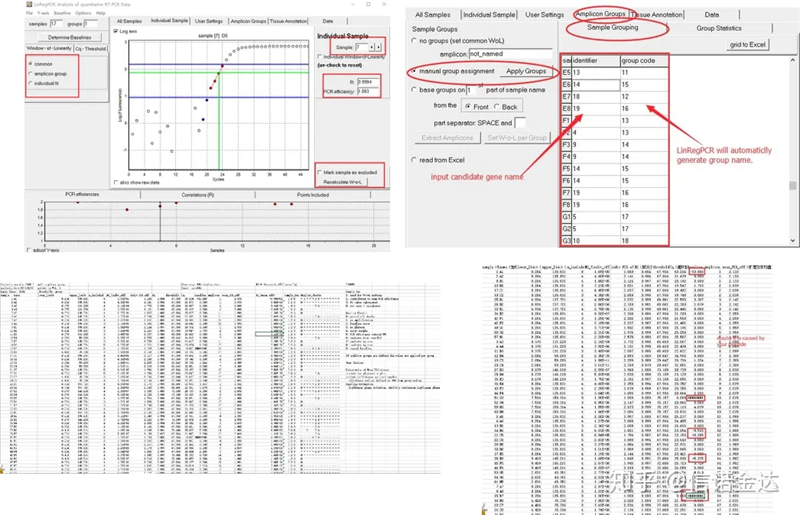
Fig 8 Sortie des résultats et des données
Processus expérimental :
Exigences de qualité de l'ARN :
Pureté:1.72,0 indique qu'il peut y avoir de l'isothiocyanate résiduel.L'acide nucléique propre A260/A230 devrait être autour de 2. S'il y a une forte absorption à 230 nm, cela indique qu'il y a des composés organiques tels que les ions phénate.De plus, il peut être détecté par électrophorèse sur gel d'agarose à 1,5 %.Pointez le marqueur, car le ssRNA n'a pas de dénaturation et le logarithme du poids moléculaire n'a pas de relation linéaire, et le poids moléculaire ne peut pas être correctement exprimé.Concentration : Théoriquementpasmoins de 100 ng/ul, si la concentration est trop faible, la pureté est généralement faible et non élevée
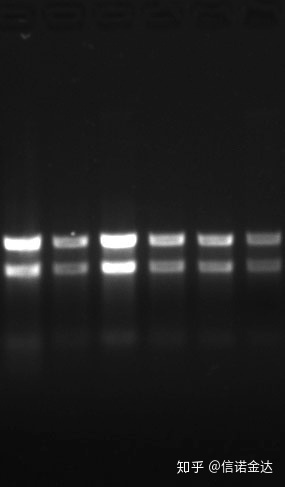
Gel d'ARN Fig9
De plus, si l'échantillon est précieux et que la concentration d'ARN est élevée, il est recommandé de l'aliquoter après extraction et de diluer l'ARN à une concentration finale de 100-300ng/ul pour la transcription inverse.Dansle processus de transcription inverse, lorsque l'ARNm est transcrit, des amorces oligo (dt) qui peuvent se lier spécifiquement aux queues polyA sont utilisées pour la transcription inverse, tandis que l'ARNlnc et l'ARNcirc utilisent des amorces hexamères aléatoires (Random 6 mer) pour la transcription inverse de l'ARN total. Pour le miARN, des amorces de boucle de cou spécifiques au miARN sont utilisées pour la transcription inverse.De nombreuses entreprises ont maintenant lancé des kits de résidus spéciaux.Pour la méthode tige-boucle, la méthode de queue est plus pratique, à haut débit et économe en réactifs, mais l'effet de la distinction des miARN de la même famille ne devrait pas être aussi bon que la méthode tige-boucle.Chaque kit de transcription inverse a des exigences pour la concentration d'amorces spécifiques au gène (stem-boucles).La référence interne utilisée pour les miARN est U6.Dans le processus d'inversion tige-boucle, un tube de U6 doit être inversé séparément, et les amorces avant et arrière de U6 doivent être ajoutées directement.Le circRNA et lncRNA peuvent utiliser les HKG comme référence interne.Dansdétection d'ADNc,
s'il n'y a pas de problème avec l'ARN, l'ADNc devrait également convenir.Cependant, si la perfection de l'expérience est recherchée, il est préférable d'utiliser un gène de référence interne (gène de référence, RG) qui peut distinguer gDNA de cds.Généralement, RG est un gène de ménage., HKG) comme le montre la figure 10 ;À cette époque, je fabriquais des protéines de stockage de soja et j'utilisais l'actine7 contenant des introns comme référence interne.La taille du fragment amplifié de cette amorce dans l'ADNg était de 452 pb, et si l'ADNc était utilisé comme matrice, elle était de 142 pb.Ensuite, les résultats du test ont révélé qu'une partie de l'ADNc était en fait contaminée par l'ADNg, et cela a également prouvé qu'il n'y avait aucun problème avec le résultat de la transcription inverse, et il pouvait être utilisé comme matrice pour la PCR.Il est inutile de faire une électrophorèse sur gel d'agarose directement avec de l'ADNc, et c'est une bande diffuse, ce qui n'est pas convaincant.
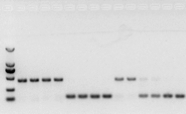
Fig 10 Détection d'ADNc
La détermination des conditions de qPCRest généralement pas de problème selon le protocole du kit, principalement dans l'étape de la valeur tm.Si certaines amorces ne sont pas bien conçues lors de la conception des amorces, ce qui entraîne une grande différence entre la valeur tm et les 60 °C théoriques, il est recommandé que l'ADNc Après le mélange des échantillons, exécutez une PCR en gradient avec des amorces et essayez d'éviter de régler la température sans bandes comme valeur TM.
L'analyse des données
La méthode conventionnelle de traitement PCR quantitatif à fluorescence relative est essentiellement selon 2-ΔΔCT.Modèle de traitement de données.
Produits connexes:
PCR en temps réel facileTM –Taqman
PCR en temps réel facileTM –SYBR VERT I
RT Easy I (Master Premix pour la synthèse d'ADNc premier brin)
RT Easy II (Master Premix pour la synthèse d'ADNc premier brin pour qPCR)
Heure de publication : 14 mars 2023



